AI 全栈 / 已完成
AI 全栈学习导航
从编程基础、前后端、AI 基础、大模型应用到部署运营,建立 AI 全栈学习地图。
返回文章积累一句话:AI 全栈不是“什么都精通”,而是能把前端、后端、数据、大模型和部署串起来,做出真正能用的 AI 产品。
本篇学完你会什么:知道 AI 产品通常由哪些层组成,先学什么、后学什么,以及什么时候该学 RAG、工具调用、Agent、部署和运营。
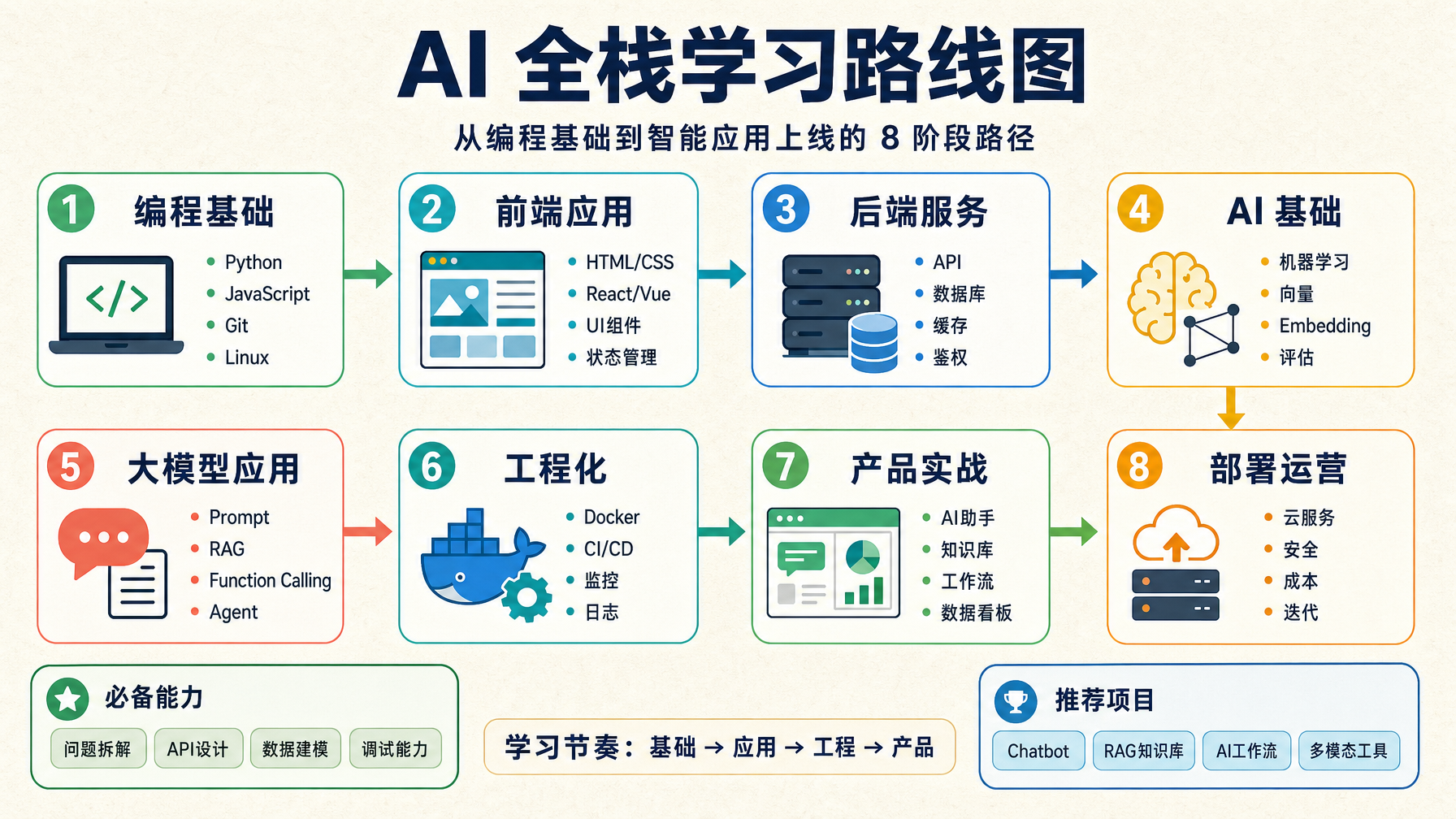
1. AI 全栈到底是什么
传统全栈工程师主要做:
- 前端页面
- 后端接口
- 数据库
- 部署上线
AI 全栈在这个基础上多了几块:
- 会调用大模型 API
- 会写 Prompt
- 会做 RAG 知识库
- 会处理向量和 Embedding
- 会设计 Agent 或工作流
- 会评估 AI 输出质量
- 会控制成本、延迟和安全风险
简单说,AI 全栈工程师要能做出这种产品:
用户打开网页,上传资料,向 AI 提问,AI 查资料、调用工具、生成结果,系统还能记录数据、控制权限、稳定上线。
2. 学习顺序不要反
很多人一上来就学 Agent、RAG、Function Calling,结果越学越乱。
先把这几个词说清楚:
| 名词 | 大白话 | 什么时候学 |
|---|---|---|
| Prompt | 给模型的任务说明 | 最先学 |
| RAG | 先查资料,再让模型回答 | 会调模型后 |
| Tool / Function Calling | 让模型在需要时调用你写的函数 | 会写后端接口后 |
| Agent | 能自己判断下一步该查资料、调工具还是继续回答的流程 | 基础链路稳定后 |
更合理的顺序是:
编程基础
-> 前端应用
-> 后端服务
-> AI 基础
-> 大模型应用
-> 工程化
-> 产品实战
-> 部署运营你可以把它想成盖楼:
- 编程基础是地基
- 前后端是楼体
- AI 是智能设备
- 工程化是水电系统
- 产品实战是装修和交付
- 部署运营是长期维护
3. 8 个学习阶段
阶段 1:编程基础
目标:能独立写小程序、调接口、读懂报错。
重点学:
- Python
- JavaScript / TypeScript
- Git
- Linux 基础
- HTTP / JSON
- 命令行
建议练习:
- 写一个命令行待办工具
- 用 Python 调一个公开 API
- 用 Git 管理自己的代码
过关标准:
- 能看懂基本代码
- 能自己定位简单报错
- 能把代码提交到 Git 仓库
阶段 2:前端应用
目标:能做一个用户可以操作的网页。
重点学:
- HTML / CSS
- React 或 Vue
- 表单、列表、弹窗、路由
- 状态管理
- UI 组件库
- 基础交互体验
建议练习:
- 做一个 ChatGPT 风格聊天页面
- 做一个文件上传页面
- 做一个带搜索和筛选的知识库列表
过关标准:
- 页面能正常交互
- 移动端和桌面端不乱
- 用户知道下一步该点哪里
阶段 3:后端服务
目标:能给前端提供稳定接口。
重点学:
- REST API
- 数据库:PostgreSQL / MySQL
- Redis 缓存
- 登录鉴权
- 文件上传
- 日志和错误处理
建议练习:
- 做用户登录
- 做文章 CRUD
- 做聊天记录保存
- 做文件上传和下载
过关标准:
- 前端能通过 API 读写数据
- 数据能持久保存
- 接口出错时能返回清晰错误
阶段 4:AI 基础
目标:理解 AI 应用背后的几个核心词。
重点学:
- Token
- Prompt
- Embedding
- 向量数据库
- 相似度搜索
- 模型上下文
- Temperature
- 评估
不用一开始就深学数学。先知道它们解决什么问题。
例如:
- Prompt:告诉模型要做什么
- Token:模型读写文字的单位
- Embedding:把文字变成数字坐标
- 向量数据库:用来找“意思相近”的资料
- RAG:先查资料,再让模型回答
过关标准:
- 知道普通聊天和 RAG 的区别
- 知道为什么模型会胡说
- 知道如何减少胡说
阶段 5:大模型应用
目标:能做一个真正有用的 AI 功能。
重点学:
- OpenAI / 兼容 API 调用
- Prompt 结构化
- Streaming 流式输出
- Function Calling
- RAG
- Agent
- 多模态:图片、语音、文档
建议练习:
- AI 聊天助手
- PDF 问答
- 企业知识库
- 自动生成日报
- 调用工具的 AI 助手
过关标准:
- AI 能基于资料回答
- 回答过程可控
- 出错时能兜底
- 成本和速度可接受
阶段 6:工程化
目标:让项目不只是“本地能跑”,而是能稳定交付。
重点学:
- Docker
- 环境变量
- CI/CD
- 日志
- 监控
- 队列
- 限流
- 错误追踪
建议练习:
- 把项目 Docker 化
- 加
.env配置 - 写部署脚本
- 给 AI 调用加超时和重试
- 记录每次模型调用成本
过关标准:
- 换一台机器也能跑起来
- 出问题能查日志
- API key 不写死在代码里
阶段 7:产品实战
目标:把技术组合成完整产品。
推荐项目:
- AI Chatbot
练前端聊天、流式输出、历史记录。
- RAG 知识库
练文件解析、Embedding、向量检索、引用来源。
- AI 工作流工具
练多步骤任务、工具调用、状态管理。
- 数据分析助手
练表格解析、图表生成、自然语言查询。
- 多模态创作工具
练图片生成、提示词管理、素材保存。
过关标准:
- 有完整用户流程
- 有登录和权限
- 有数据存储
- 有错误处理
- 能部署给别人试用
阶段 8:部署运营
目标:让 AI 产品长期可用。
重点学:
- 云服务器
- 对象存储
- 数据库备份
- HTTPS
- API 限额
- 成本统计
- 用户反馈
- 安全审计
AI 产品尤其要注意:
- 模型调用很贵
- 用户输入不可控
- 输出可能不稳定
- 私密数据不能乱传
- 长文档处理容易超时
过关标准:
- 线上服务稳定
- 费用可控
- 用户数据安全
- 能持续迭代
4. 推荐学习项目路线
如果你想边学边做,可以按这个顺序:
- 静态学习路线页面
练 HTML/CSS 和页面结构。
- AI 聊天页面
练前端交互和接口调用。
- 带登录的 AI 助手
练用户系统和聊天记录。
- PDF 知识库问答
练 RAG、文件解析、向量库。
- 企业内部 AI 工具台
练权限、工作流、部署、监控。
- 可运营的 AI SaaS Demo
练支付、限额、成本、日志、反馈。
5. 常见误区
| 误区 | 正确做法 |
|---|---|
| 一上来学 Agent | 先学 API、Prompt、RAG |
| 只会调模型 | 要会做前后端和数据存储 |
| Prompt 写得越长越好 | 应该结构清晰、约束明确 |
| 本地跑通就算完成 | 还要能部署、监控、排错 |
| 不管成本 | 每次模型调用都要有成本意识 |
| 迷信模型能力 | 重要场景要做校验和兜底 |
6. 总结路线表
| 阶段 | 目标 | 代表技能 |
|---|---|---|
| 编程基础 | 能写代码和调试 | Python、JS、Git |
| 前端应用 | 能做用户界面 | React/Vue、UI、状态 |
| 后端服务 | 能提供数据接口 | API、数据库、鉴权 |
| AI 基础 | 理解模型应用原理 | Token、Embedding、向量 |
| 大模型应用 | 能做 AI 功能 | Prompt、RAG、Agent |
| 工程化 | 能稳定交付 | Docker、CI/CD、日志 |
| 产品实战 | 能做完整产品 | Chatbot、知识库、工作流 |
| 部署运营 | 能长期运行 | 云服务、安全、成本 |
最后记住一句话:
AI 全栈的核心不是追热点,而是把“模型能力”变成“用户能用的产品”。