数据库 / 已完成
FastAPI 使用 Alembic 管理数据库表结构
理解数据库迁移、revision、upgrade、downgrade,以及正式项目改表时应该怎么做。
返回文章积累这篇教程讲的是:FastAPI 项目里,数据库表结构应该怎么正规管理。
一句话:Alembic 就像数据库的“装修记录本”,每次建表、加字段、改字段、删字段,都写成一份迁移文件,这样本地、测试、生产环境都能按同一套步骤升级。
1. 为什么不能一直用自动建表
前一篇 CRUD 教程里,为了让你快速跑起来,我们用了这种方式:
await conn.run_sync(Base.metadata.create_all)它的意思是:启动服务时,如果数据库里没有表,就自动创建。
这对练习很方便,但正式项目不能长期靠它。
原因很简单:create_all 更像“看到没有桌子就摆一张桌子”,但它不擅长记录装修过程。
比如你后来做了这些事:
给 users 表加 avatar 字段
把 username 改成唯一索引
新增 articles 表
把 status 字段从 bool 改成 int
删除一个旧字段create_all 不会帮你清楚记录:
- 哪天改了什么。
- 改动顺序是什么。
- 线上数据库应该从哪个版本升级到哪个版本。
- 如果出错,怎么回滚。
正式项目需要的是:
每次数据库结构变化都有记录
每个环境都按同一份记录升级
出问题可以知道是哪一步出错
必要时可以回滚这就是 Alembic 要解决的问题。
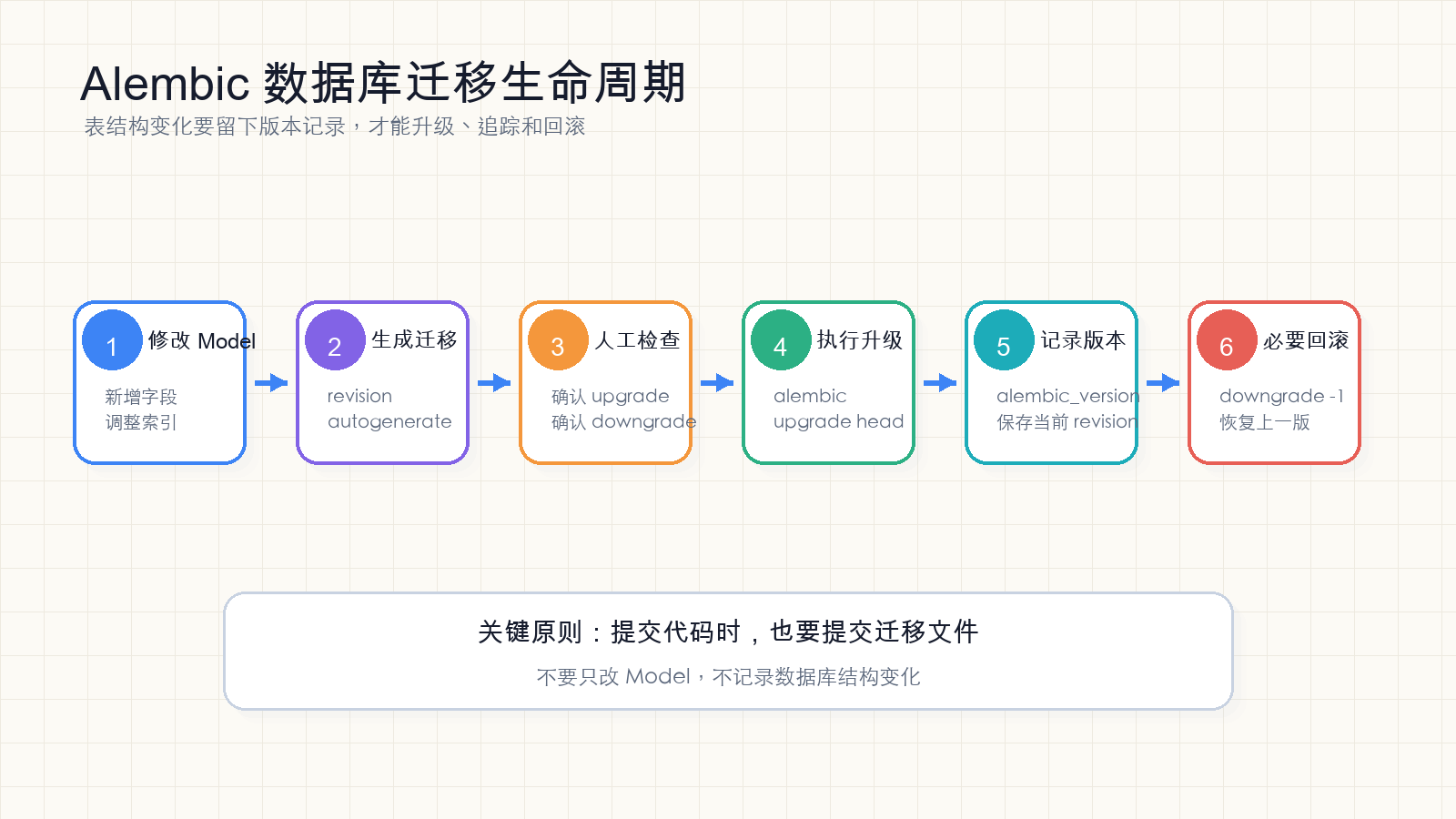
2. Alembic 是什么
Alembic 是 SQLAlchemy 官方生态里常用的数据库迁移工具。
你可以把它理解成:
Git 管代码版本
Alembic 管数据库结构版本代码变了,你会提交 Git commit。
数据库表结构变了,你就应该创建 Alembic migration。
对比一下:
| 事情 | 代码世界 | 数据库世界 |
|---|---|---|
| 记录变化 | Git commit | Alembic revision |
| 升到最新 | git pull | alembic upgrade head |
| 回到旧版本 | git checkout | alembic downgrade |
| 看历史 | git log | alembic history |
| 当前版本 | git rev-parse HEAD | alembic current |
大白话:Alembic 就是数据库结构的版本管理工具。
3. 迁移文件到底记录什么
一份 Alembic 迁移文件通常长这样:
"""add users table"""
from alembic import op
import sqlalchemy as sa
revision = "20260429_add_users"
down_revision = None
branch_labels = None
depends_on = None
def upgrade():
op.create_table(
"users",
sa.Column("id", sa.Integer(), primary_key=True),
sa.Column("username", sa.String(length=50), nullable=False),
)
def downgrade():
op.drop_table("users")重点看两个函数:
| 函数 | 大白话 |
|---|---|
upgrade() | 升级时做什么,比如建表、加字段 |
downgrade() | 回滚时做什么,比如删表、删字段 |
如果你执行:
alembic upgrade headAlembic 就会执行 upgrade()。
如果你执行:
alembic downgrade -1Alembic 就会执行上一份迁移的 downgrade()。
4. 本文使用的项目结构
继续用 FastAPI + SQLAlchemy async 的标准结构:
fastapi-api-service/
├── app/
│ ├── main.py
│ ├── core/
│ │ ├── config.py
│ │ └── database.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ └── user.py
│ └── schemas/
├── alembic/
│ ├── env.py
│ ├── script.py.mako
│ └── versions/
├── alembic.ini
├── requirements.txt
└── .env其中:
| 文件 | 作用 |
|---|---|
app/core/config.py | 读取数据库地址 |
app/core/database.py | 定义 Base 和数据库 engine |
app/models/ | 放 SQLAlchemy 模型 |
alembic/env.py | 告诉 Alembic 去哪里找数据库和模型 |
alembic/versions/ | 存放每一份迁移文件 |
alembic.ini | Alembic 配置文件 |
5. 安装 Alembic
如果你已经按前几篇装过依赖,只要确认 requirements.txt 里有:
alembic==1.14.0
sqlalchemy==2.0.36
asyncpg==0.30.0安装:
pip install -r requirements.txt或者单独安装:
pip install alembic sqlalchemy asyncpg确认命令可用:
alembic --help能看到帮助信息就说明安装成功。
6. 初始化 Alembic
在项目根目录执行:
alembic init alembic执行后会生成:
alembic/
env.py
README
script.py.mako
versions/
alembic.ini大白话:
| 文件 | 意思 |
|---|---|
alembic.ini | Alembic 总配置 |
alembic/env.py | Alembic 真正运行时会执行的配置脚本 |
alembic/versions/ | 每次迁移文件都放这里 |
script.py.mako | 生成迁移文件时使用的模板 |
如果你的项目使用异步数据库连接,也可以用 Alembic 官方提供的 async 模板:
alembic init -t async alembic不过很多已有项目是先 alembic init alembic,再手动改 env.py。下面就按这种方式讲,因为更容易看懂每一步。
7. 配置 Alembic 连接 FastAPI 项目
Alembic 需要知道两件事:
1. 数据库在哪里
2. 你的 SQLAlchemy Model 在哪里数据库地址在:
app/core/config.pyBase 在:
app/core/database.pyModel 在:
app/models/7.1 配置 config.py
app/core/config.py:
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
DATABASE_URL: str = "postgresql+asyncpg://postgres:password@localhost:5432/appdb"
class Config:
env_file = ".env"
settings = Settings().env:
DATABASE_URL=postgresql+asyncpg://postgres:password@localhost:5432/appdb7.2 配置 database.py
app/core/database.py:
from sqlalchemy.ext.asyncio import async_sessionmaker, create_async_engine
from sqlalchemy.orm import DeclarativeBase
from app.core.config import settings
engine = create_async_engine(settings.DATABASE_URL, echo=False)
AsyncSessionLocal = async_sessionmaker(engine, expire_on_commit=False)
class Base(DeclarativeBase):
pass7.3 修改 alembic/env.py
把 alembic/env.py 改成适配异步 SQLAlchemy 的版本:
import asyncio
from logging.config import fileConfig
from alembic import context
from sqlalchemy import pool
from sqlalchemy.ext.asyncio import create_async_engine
from app.core.config import settings
from app.core.database import Base
from app.models import user # noqa
config = context.config
if config.config_file_name is not None:
fileConfig(config.config_file_name)
target_metadata = Base.metadata
def run_migrations_offline():
context.configure(
url=settings.DATABASE_URL,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def do_run_migrations(connection):
context.configure(
connection=connection,
target_metadata=target_metadata,
compare_type=True,
)
with context.begin_transaction():
context.run_migrations()
async def run_migrations_online():
connectable = create_async_engine(settings.DATABASE_URL, poolclass=pool.NullPool)
async with connectable.connect() as connection:
await connection.run_sync(do_run_migrations)
await connectable.dispose()
if context.is_offline_mode():
run_migrations_offline()
else:
asyncio.run(run_migrations_online())最重要的是这几行:
from app.core.database import Base
from app.models import user # noqa
target_metadata = Base.metadata意思是:告诉 Alembic,“你要对比的目标表结构,就在这些 SQLAlchemy Model 里”。
如果以后你新增了 article.py,也要导入:
from app.models import article # noqa否则 Alembic 不知道有这张表。
8. 写第一个 Model
创建:
app/models/base.pyimport datetime
from sqlalchemy import DateTime, func
from sqlalchemy.orm import Mapped, mapped_column
class TimestampMixin:
created_at: Mapped[datetime.datetime] = mapped_column(
DateTime(timezone=True),
server_default=func.now(),
)
updated_at: Mapped[datetime.datetime] = mapped_column(
DateTime(timezone=True),
server_default=func.now(),
onupdate=func.now(),
)创建:
app/models/user.pyfrom sqlalchemy import Boolean, Integer, String
from sqlalchemy.orm import Mapped, mapped_column
from app.core.database import Base
from app.models.base import TimestampMixin
class User(Base, TimestampMixin):
__tablename__ = "users"
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
username: Mapped[str] = mapped_column(String(50), unique=True, nullable=False)
email: Mapped[str] = mapped_column(String(100), unique=True, nullable=False)
status: Mapped[bool] = mapped_column(Boolean, default=True)现在 Python 里已经有了 users 表的“设计图”,但数据库里还没有真正的表。
下一步就是让 Alembic 根据这个设计图生成迁移文件。
9. 生成第一份迁移
执行:
alembic revision --autogenerate -m "create users table"你会看到类似输出:
Generating .../alembic/versions/xxxx_create_users_table.py ... done打开生成的文件,大概会看到:
def upgrade():
op.create_table(
"users",
sa.Column("id", sa.Integer(), autoincrement=True, nullable=False),
sa.Column("username", sa.String(length=50), nullable=False),
sa.Column("email", sa.String(length=100), nullable=False),
sa.Column("status", sa.Boolean(), nullable=False),
sa.Column("created_at", sa.DateTime(timezone=True), server_default=sa.text("now()"), nullable=False),
sa.Column("updated_at", sa.DateTime(timezone=True), server_default=sa.text("now()"), nullable=False),
sa.PrimaryKeyConstraint("id"),
sa.UniqueConstraint("email"),
sa.UniqueConstraint("username"),
)
def downgrade():
op.drop_table("users")重点:生成后一定要人工检查。
检查什么?
表名对不对
字段名对不对
字段类型对不对
nullable 是否对
unique 约束是否对
downgrade 是否合理
有没有误删其他表Alembic 官方也明确提醒:自动生成不是完美的,生成出来的迁移候选文件必须人工审查。
10. 执行迁移
生成迁移文件后,数据库还没有变。
你需要执行:
alembic upgrade head大白话:把数据库升级到最新版本。
执行成功后,数据库里会出现:
users
alembic_version其中:
| 表 | 作用 |
|---|---|
users | 你的业务表 |
alembic_version | Alembic 自己记录当前数据库版本的表 |
查看当前版本:
alembic current查看历史:
alembic history11. 修改表结构并生成第二份迁移
现在假设你要给用户表加头像字段。
修改:
app/models/user.py新增字段:
avatar: Mapped[str | None] = mapped_column(String(300), nullable=True)完整片段:
class User(Base, TimestampMixin):
__tablename__ = "users"
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
username: Mapped[str] = mapped_column(String(50), unique=True, nullable=False)
email: Mapped[str] = mapped_column(String(100), unique=True, nullable=False)
avatar: Mapped[str | None] = mapped_column(String(300), nullable=True)
status: Mapped[bool] = mapped_column(Boolean, default=True)生成新迁移:
alembic revision --autogenerate -m "add user avatar"生成文件里应该类似:
def upgrade():
op.add_column("users", sa.Column("avatar", sa.String(length=300), nullable=True))
def downgrade():
op.drop_column("users", "avatar")检查没问题后执行:
alembic upgrade head到这里,数据库里的 users 表就有 avatar 字段了。
12. 回滚迁移
如果刚才加头像字段后发现不该加,可以回滚一步:
alembic downgrade -1意思是:退回上一个版本。
也可以退到指定 revision:
alembic downgrade <revision_id>退到最初:
alembic downgrade base但正式环境要非常小心。
因为回滚可能会删字段、删表,也就可能丢数据。
比如:
def downgrade():
op.drop_column("users", "avatar")如果这个字段里已经有用户头像数据,执行回滚后这些数据就没了。
所以生产环境回滚前要问清楚:
会不会删数据?
有没有备份?
业务是否允许?
回滚后代码是否匹配旧表结构?13. 常用命令小抄
| 命令 | 大白话 |
|---|---|
alembic init alembic | 初始化 Alembic |
alembic init -t async alembic | 初始化异步模板 |
alembic revision -m "message" | 创建空迁移文件 |
alembic revision --autogenerate -m "message" | 根据 Model 自动生成迁移 |
alembic upgrade head | 升级到最新 |
alembic downgrade -1 | 回滚一步 |
alembic downgrade base | 回滚到最初 |
alembic current | 查看当前数据库版本 |
alembic history | 查看迁移历史 |
alembic heads | 查看最新迁移头 |
alembic show <revision> | 查看某个迁移详情 |
最常用组合:
alembic revision --autogenerate -m "add xxx"
alembic upgrade head14. 自动生成迁移的坑
--autogenerate 很好用,但不能盲信。
Alembic 自动生成主要是做一件事:
拿数据库现在的结构
对比
拿 SQLAlchemy Model 里的结构
得出差异
生成迁移候选文件它通常能发现:
| 变化 | 通常能否发现 |
|---|---|
| 新增表 | 能 |
| 删除表 | 能 |
| 新增字段 | 能 |
| 删除字段 | 能 |
| nullable 改动 | 能 |
| 基础索引和唯一约束 | 通常能 |
| 外键约束 | 通常能 |
| 字段类型变化 | 通常能,但要检查 |
| 字段重命名 | 不一定 |
| 表重命名 | 不一定 |
| 复杂默认值变化 | 不一定 |
| 数据迁移 | 不会自动理解业务 |
14.1 字段重命名的坑
比如你把:
username改成:
nameAlembic 可能会理解成:
删除 username
新增 name这会导致原来的 username 数据丢掉。
更安全的迁移应该手写:
def upgrade():
op.alter_column(
"users",
"username",
new_column_name="name",
existing_type=sa.String(length=50),
)
def downgrade():
op.alter_column(
"users",
"name",
new_column_name="username",
existing_type=sa.String(length=50),
)这里的 existing_type 是告诉 Alembic:这个字段原本是什么类型。不同数据库对改字段名的要求不完全一样,写清楚会更稳。
所以看到自动生成了 drop_column 和 add_column,一定要警惕。字段重命名通常应该手写迁移,不要让旧数据被误删。
14.2 非空字段的坑
已有表里已经有数据,现在你加一个非空字段:
phone: Mapped[str] = mapped_column(String(20), nullable=False)自动迁移可能生成:
op.add_column("users", sa.Column("phone", sa.String(length=20), nullable=False))如果表里已有老数据,这条迁移可能失败。
更稳的做法:
def upgrade():
op.add_column("users", sa.Column("phone", sa.String(length=20), nullable=True))
op.execute("UPDATE users SET phone = '' WHERE phone IS NULL")
op.alter_column("users", "phone", nullable=False)意思是:
先允许为空
填补旧数据
再改成不允许为空14.3 数据迁移不要乱写
结构迁移是:
建表、加字段、改字段、建索引数据迁移是:
把旧字段的数据搬到新字段
初始化一批默认数据
修复历史脏数据Alembic 可以写少量数据迁移,比如初始化字典数据:
op.bulk_insert(
my_table,
[
{"code": "enabled", "name": "启用"},
{"code": "disabled", "name": "禁用"},
],
)但复杂数据迁移要谨慎,很多时候应该写独立脚本,先备份、再处理。
15. 正式项目里的安全流程
正式项目不要直接这样:
改完 Model
alembic revision --autogenerate
alembic upgrade head
上线更安全的流程:
1. 修改 Model
2. 生成迁移文件
3. 人工检查迁移文件
4. 本地空库执行 alembic upgrade head
5. 本地有旧数据的库执行 upgrade 测试
6. 如有 downgrade,测试 downgrade 是否可用
7. 提交代码和迁移文件
8. 测试环境执行迁移
9. 确认接口和数据正常
10. 生产环境备份数据库
11. 生产环境执行迁移
12. 部署新代码15.1 代码和迁移要一起提交
如果你只提交 Model,不提交迁移文件,别人拉代码后数据库不会变。
如果你只提交迁移,不提交 Model,代码和数据库结构会不一致。
所以要一起提交:
app/models/user.py
alembic/versions/xxxx_add_user_avatar.py15.2 生产环境先备份
涉及删字段、删表、大批量更新时,先备份数据库。
最怕的是:
迁移执行成功了
但是删错字段了
而且没有备份这类事故很难救。
15.3 不要随便改已经上线的迁移文件
已经在测试或生产执行过的迁移文件,不要随便改内容。
因为别人的数据库已经记录了这个 revision。
如果要继续改,通常应该新增一份迁移,而不是回头改旧文件。
16. 常见错误和排查
16.1 Target database is not up to date
通常是:数据库还没升级到最新,你又想生成新迁移。
先执行:
alembic upgrade head再生成:
alembic revision --autogenerate -m "xxx"16.2 自动生成迁移是空的
可能原因:
- 你忘了改 Model。
alembic/env.py没导入新 Model。target_metadata没设置成Base.metadata。- 你连错数据库了。
重点检查:
from app.core.database import Base
from app.models import user # noqa
target_metadata = Base.metadata16.3 ModuleNotFoundError: No module named 'app'
通常是你执行命令的位置不对。
应该在项目根目录执行:
alembic upgrade head项目根目录就是能看到 app/、alembic/、alembic.ini 的地方。
如果你的目录特殊,可以临时设置:
PYTHONPATH=. alembic upgrade head16.4 数据库连接失败
检查 .env:
DATABASE_URL=postgresql+asyncpg://postgres:password@localhost:5432/appdb常见问题:
| 问题 | 现象 |
|---|---|
| 数据库没启动 | 连接失败 |
| 数据库名写错 | database does not exist |
| 密码写错 | password authentication failed |
| 端口写错 | connection refused |
| Docker 内外地址混用 | 本地不能访问容器服务名 |
16.5 执行迁移时提示表已经存在
可能原因:
- 你之前用
create_all建过表。 - Alembic 以为数据库是空的。
- 数据库结构和 migration 记录不一致。
练习项目可以清空数据库重来。
正式项目不要直接删库,需要根据实际情况处理:
alembic stamp headstamp 的意思是:不执行迁移,只把数据库标记为某个版本。
这个命令有风险,只有在你确认数据库结构已经和迁移文件一致时才用。
16.6 migration 里出现奇怪的删表删字段
先停手,不要执行。
通常是:
- 连错数据库。
- Model 没导入完整。
- Alembic 把重命名误判成删除加新增。
- 多人开发时 migration 分支乱了。
处理方式:
先人工检查 migration
确认是不是误删
必要时手动改 migration
再执行 upgrade17. 学完后下一步
建议下一篇讲:
大白话讲解——FastAPI 登录认证和 JWT 鉴权因为现在你已经会:
- 搭标准 API 服务。
- 连接数据库。
- 写增删改查。
- 用 Alembic 管表结构。
下一步就该解决:
谁能登录?
登录后怎么证明自己?
哪些接口必须登录?
哪些接口必须管理员?
退出登录后 Token 怎么失效?这就是后端系统的“门禁”。
18. 总结表
| 名词 | 大白话 |
|---|---|
| Alembic | 数据库结构版本管理工具 |
| migration | 一次数据库结构变化记录 |
| revision | 迁移版本号 |
upgrade() | 升级时执行的操作 |
downgrade() | 回滚时执行的操作 |
head | 最新版本 |
base | 最初版本 |
alembic_version | Alembic 在数据库里记录当前版本的表 |
--autogenerate | 根据 Model 和数据库差异自动生成迁移候选文件 |
target_metadata | Alembic 用来对比的目标表结构 |
最后记住一句话:
Model 是表结构设计图,
Migration 是装修施工单,
Database 是真正装修好的房子,
Alembic 负责按施工单一步一步装修。正式项目里,数据库结构变化一定要留下迁移文件。
这不是麻烦,这是保护线上数据的安全绳。