稳定性 / 闯关模式
后端服务稳定性
学习异常、日志、健康检查、超时、重试、限流、降级和监控。
一句话:稳定性不是“代码不报错”这么简单,而是服务出问题时能发现、能定位、能恢复,并且不要让一个小问题拖垮整个系统。
本篇学完你会什么:知道异常、日志、健康检查、超时、重试、监控、限流分别解决什么问题。
1. 稳定性到底是什么
稳定服务应该做到:
- 正常请求能返回
- 错误请求有清楚提示
- 服务挂了能被发现
- 外部服务慢了不会一直卡住
- 出问题能查日志
- 压力太大时能保护自己
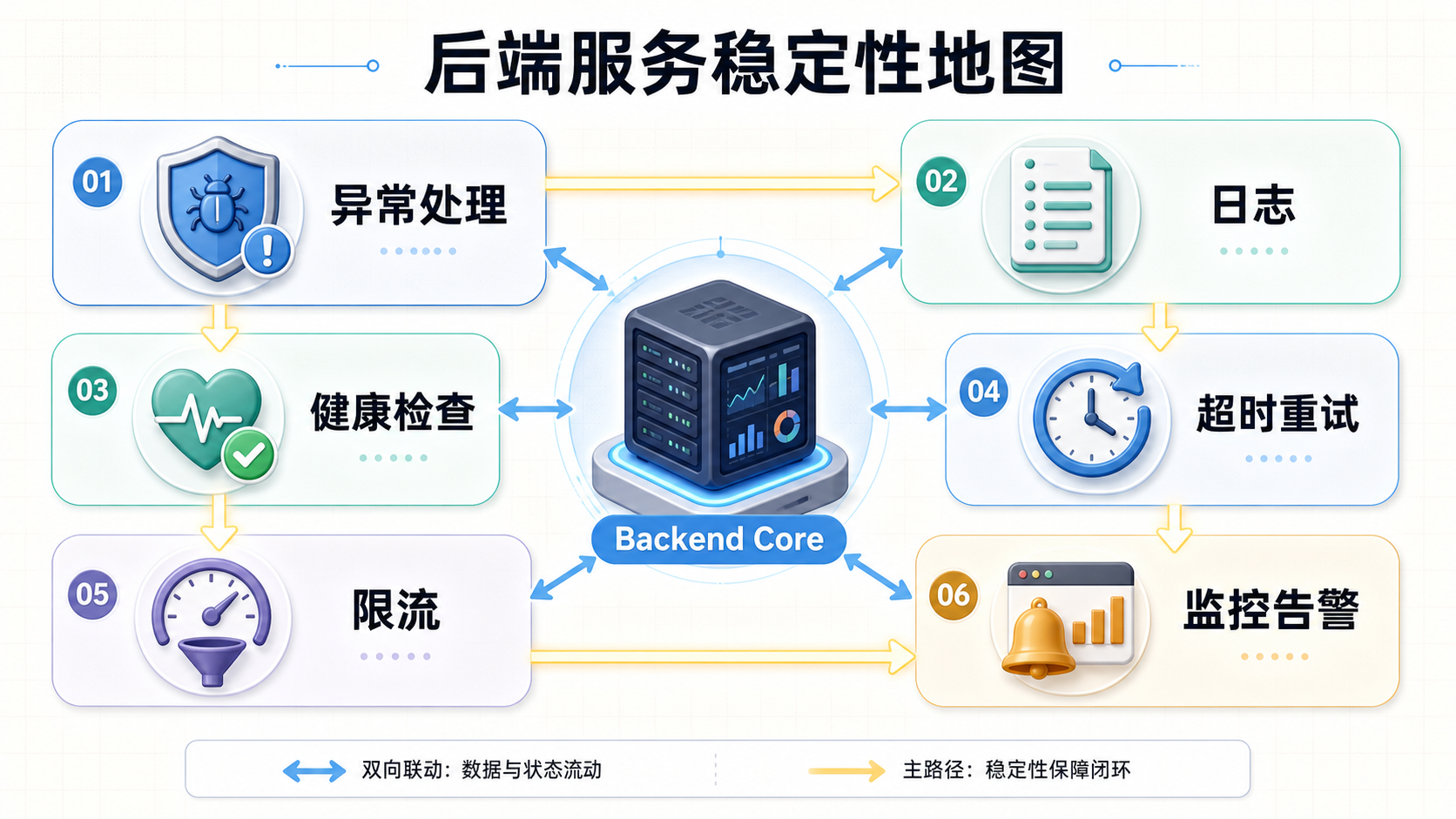
2. 统一异常处理
不要在每个接口里随便返回:
return {"error": "xxx"}更推荐用明确的异常:
from fastapi import HTTPException
raise HTTPException(status_code=404, detail="用户不存在")常用错误:
| 状态码 | 场景 |
|---|---|
| 400 | 请求参数逻辑错误 |
| 401 | 未登录 |
| 403 | 没权限 |
| 404 | 资源不存在 |
| 409 | 数据冲突 |
| 429 | 请求太频繁 |
| 500 | 服务内部错误 |
3. 日志
日志是系统的行车记录仪。
应该记录:
- 请求路径
- 请求耗时
- 当前用户 id
- 错误堆栈
- 外部 API 调用结果
不应该记录:
- 密码
- 完整 token
- API key
- 用户隐私原文
简单日志:
import logging
logger = logging.getLogger(__name__)
logger.info("create article user_id=%s title=%s", user.id, payload.title)
logger.exception("create article failed")4. 请求追踪 ID
请求追踪 ID 就是给每次请求发一个编号。
request_id=abc123好处:前端报错时给你这个编号,你可以在日志里找到同一次请求的所有记录。
常见 Header:
X-Request-Id: abc1235. 健康检查
最基础:
@app.get("/health")
async def health():
return {"status": "ok"}更完整可以检查:
- API 是否活着
- 数据库是否能连
- Redis 是否能连
注意:健康检查不能太慢,不要做复杂业务查询。
6. 超时
调用外部服务一定要设置超时。
不要这样:
response = await client.get(url)更推荐:
response = await client.get(url, timeout=10)大白话:不能让一个第三方服务慢,把你的接口一直拖着。
7. 重试
重试适合临时失败,比如网络抖动。
不适合:
- 参数错误
- 权限错误
- 明确的业务失败
重试要注意:
- 次数有限
- 间隔递增
- 不要重复扣款、重复发短信
8. 限流和降级
限流:请求太多时拒绝一部分。
1 分钟最多 60 次
超过返回 429降级:非核心功能失败,不影响主流程。
例子:
推荐系统挂了 -> 仍然展示默认列表
Redis 挂了 -> 直接查数据库,但减少重缓存逻辑
AI 服务超时 -> 返回稍后再试9. 监控和告警
日志是出问题后查,监控是提前看到趋势。
重点指标:
| 指标 | 意思 |
|---|---|
| QPS | 每秒请求数 |
| 错误率 | 失败请求比例 |
| P95 耗时 | 95% 请求在多长时间内返回 |
| CPU/内存 | 机器压力 |
| 数据库连接数 | 数据库是否快满 |
初学阶段先做到:
- 能看日志
- 有
/health - 知道接口耗时
- 错误时能收到通知
10. 常见错误
| 问题 | 原因 | 解决 |
|---|---|---|
| 出错只能猜 | 没日志 | 关键路径加日志 |
| 外部服务慢拖垮接口 | 没超时 | 所有外部调用加 timeout |
| 重试导致重复操作 | 非幂等接口乱重试 | 只重试安全操作 |
| 用户看到一堆堆栈 | 直接暴露异常 | 统一错误返回 |
| 服务挂了没人知道 | 没健康检查和告警 | 加 /health 和监控 |
11. 稳定性检查清单
[ ] 每个业务错误有明确状态码
[ ] 未处理异常会记录堆栈
[ ] 日志不打印敏感信息
[ ] 有 /health
[ ] 外部 HTTP 调用有超时
[ ] 重试不会造成重复副作用
[ ] 高频接口有限流
[ ] Redis/第三方服务失败有降级策略
[ ] 能看到接口耗时和错误率总结表
| 名词 | 大白话 |
|---|---|
| 异常处理 | 错了要说清楚 |
| 日志 | 行车记录仪 |
| request_id | 请求编号 |
| 健康检查 | 服务是否活着 |
| 超时 | 等太久就放弃 |
| 重试 | 临时失败再试几次 |
| 限流 | 请求太多先挡住 |
| 降级 | 非核心坏了主流程还能跑 |
| 监控 | 看系统身体指标 |
下一篇建议:大白话讲解——后端测试和工程化。